4. GAN (Generative Adversarial Network, 적대적 생성모델) 소개
개념
Generator와 Discriminator의 치열한 싸움이라고 생각하면 쉽게 이해할 수 있습니다. 위조 지폐를 만드는 Generator는 경찰이 위조 지폐인지 실제로 현금인지 구별할 수 없을 정도로 진짜 같은 위조 지폐를 만들어야 합니다. 반면, 경찰 역할을 하는 Discriminator는 Generator가 만들어낸 위조 지폐를 실제 지폐와 구별할 수 있어야 합니다.
GAN의 아이디어를 처음 떠올린 Ian Goodfellow는 동료와 술을 마시다가 위 아이디어를 떠올렸고, 집에 돌아가서 하루만에 모델을 구현했다고 전해집니다.
수학적으로 이해하고 싶다면 다음의 수식(objective function)을 이해하면 됩니다 ^^
어려워 보여도 Generator와 Discriminator의 역할만 제대로 파악하고 있다면 수식을 이해하는 것은 그렇게 어렵지 않습니다. Generator는 objective function을 최소화해야 하고, Discriminator는 반대로 objective function을 최대화해야 합니다. 자세한 학습 과정은 https://youtu.be/odpjk7_tGY0 을 참고하면 좋을 것 같습니다!
종류
Vanilla GAN
- 위조 지폐범과 경찰의 예를 들며 설명했을 때 그럴 듯하게 들리는 GAN에는 약점이 두 가지 있습니다. 바로 Vanishing Gradient와 Collapse Mode 입니다. 이를 해결하기 위해 여러 가지 변형된 GAN이 탄생했습니다.
* Vanishing Gradient : D(G(z))가 0에 수렴해버리는 문제
* Collapse Mode : Generator가 Discriminator를 잘 속이는 경우, 해당 sample만 거듭하여 생성될 때 Loss function이 작아져 유사한 이미지에서 벗어날 수 없는 문제
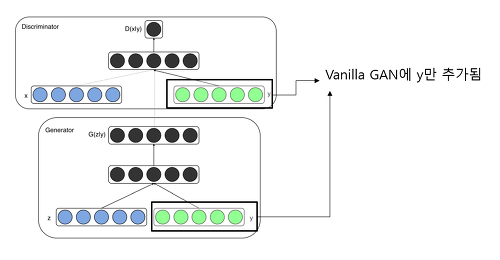
Conditional GAN (cGAN)
- 2014년 몬트리올 대학에서 발표한, 기존 GAN 모델에 조건(Condition) y를 부여하여 해당 조건을 만족시키는 이미지를 생성하는 모델입니다.
Mehdi Mirza, Conditional Generative Adversarial Nets, 2014. - y는 0부터 9까지 해당하는 label이 될 수도 있고, multi-modal 형태도 가능합니다. (Pix2Pix 모델 참고) Conditional GAN에 해당하는 대표적인 모델로는 Pix2Pix와 Cycle GAN이 있습니다.
- 수식으로 살펴보면 Vanilla GAN과 Conditional GAN의 차이가 명확하게 드러납니다.
Vanilla GAN의 objective functionConditional GAN의 objective function
Wasserstein GAN (WGAN)
- Wasserstein GAN은 앞서 언급했던 학습 과정에서 GAN의 약점(discriminator의 vanishing gradient 문제)을 보완하고 Generator - Discriminator 사이의 Nash 균형을 찾는 vanilla GAN 대신 generator에게 최적의 gradient를 제공합니다.
- 기존의 (pre) metric으로 사용되던 TV(Total Variation), KL, JS는 두 확률분포 P, Q가 전혀 겹치지 않는 상황에서는 metric이 완전히 다르다고 판단하기 때문에 불연속이 됩니다. 하지만 Martin의 증명에 따르면 GAN의 discriminator의 gradient가 학습 과정에서 소실(0으로 수렴)되기 때문에 보다 weak하면서 0이 아닌 적당한 값으로 수렴하는 새로운 metric의 필요성이 대두됩니다.
- WGAN은 discriminator 대신 critic이라는 이름의 식을 도입하는데 Lipschitz 연속 조건을 이용하여 확률분포들의 공간에서 정의한 Wasserstein 거리(metric)로 Loss function을 새롭게 정의한 모델입니다.
* WassersteinDistance : 주어진 분포를 target 분포에 일치시키는데 필요한 최소한의 거리로, 모든 결합확률분포 중에서 metric d(X, Y)의 기댓값을 가장 작게 추정한 값. 확률분포 특정 구간의 특징보다 전체적인 모양을 중시하기 때문에 타 metric에 비해 soft한 분포수렴에 속함.
*Kullback-Leibler (KL) Divergence : 대칭성과 삼각부등식 성질을 만족하지 않기 때문에 엄밀히 말해 KL Divergence는 metric은 아님
- 위 사진처럼 P와 Q라는 이름의 분포가 있다고 가정해봅시다. Step [0]과 같은 형태로 주어졌을 때 우리의 목표는 P 분포를 Q 분포처럼 만드는 것입니다. 앞서 정의한 식에 그대로 집어넣어보면 (2 + 2)/10 + 1/10 = 0.5가 Wasserstein Distance가 됩니다. KLD, JSD 역시 WD와 큰 차이 없이 metric을 계산할 수 있습니다.
- 그렇다면 아래처럼 분포 P, Q의 support가 전혀 겹치지 않는 상황은 어떻게 될까요?
- x=0일 때 measure가 정의된 분포 P와 x=0.5일 때 measure가 정의된 분포 Q의 KLD, JSD, WD를 구해보면 각각 무한대, log2, 확률변수의 절댓값이 나옵니다. KLD, JSD의 경우 확률분포 P와 Q가 완전히 다르다고 판단해버리며 metric 계산 값이 GAN의 학습과정에서 Discriminator의 gradient를 소실시키는 원인이 됩니다.
- 따라서 보다 Lipschitz continuity 가정을 추가함으로써 유연한 조건을 지닌 Wasserstein Distance는 WGAN의 critic(Discriminator 역할)이 학습되더라도 vanishing gradient 문제를 야기하지 않는 훌륭한 loss function으로 작동하게 됩니다.
LSGAN
- Hyper-parameter a, b, c를 추가하여 vanishing gradient 문제를 해결하는 손실함수를 Discriminator / Generator 학습 과정에 사용하는 모델입니다.





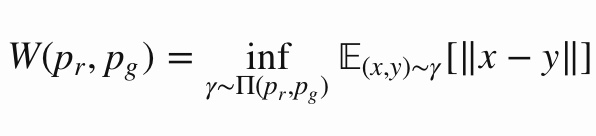









댓글