반응형
[NLP] Word Embedding : Bag of words / TFIDF / Word2Vec / fastText
1. Bag of words
- Bag of Words란 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법이다. 단어들을 가방 안에 모두 넣은 다음, 각 단어에 unique index를 부여한다. 그 후 문서에서 해당 단어가 등장하는 횟수를 기록하는 벡터를 만든다.

- 즉, 단어 사전을 미리 구축(tokenize : 띄어쓰기 or 형태소로 구분)하여 문장 속 단어 빈도를 표시하는 것이다. 이때 주의할 점은, 단어의 빈도만 고려할 뿐이지 순서까지는 생각하지 않는다는 것이다. 문서의 모든 단어를 벡터화해야하기 때문에 문자로 단어를 조합할 수 있는 경우의 수(얼마나 많을지 상상이 안 간다.)만큼 단어 사전이 방대해진다.
- Tokenization (토큰화) : 주어진 코퍼스(corpus)에서 토큰(token)이라 불리는 단위로 나누는 작업을 토큰화(tokenization)라고 부른다. 토큰의 단위가 상황에 따라 다르지만, 보통 의미있는 단위로 토큰을 정의한다. 네 가지 방식의 토큰화를 간단히 설명하겠다.

1) 띄어쓰기 단위 : ‘맛있다’, ‘맛있어요’, ‘맛있었다’ 등 같은 단어가 모두 다르게 인식되어 단어사전이 매우 커진다.
2) 문자 단위 : 각 token이 의미를 담지 못한다.(‘학’, ‘교’, ‘에’) 또한 한국어는 문자가 매우 많음. (영어는 26개에 불과함)
3) Subword 단위 (형태소) : 매우 효율적이지만 언어지식이 필요하여 컴퓨터가 알아서 할 수 없음.
4) Subword 단위 (Wordpiece(BPE)) : 빈번하게 나오는 문자를 묶어 단어사전의 수를 줄임. (‘학’, ‘교’ 따로보다 ‘학교’ 붙여쓴게 많으면 후자를 단어사전에 채택)
#### Bag of Words ####
corpus = [
'학교에 가서 수업을 들었다. 학교에 간건 오랜만이다.',
'학교에 가서 친구 얘기를 들었다.',
'내일 가서 뭐 먹지?'
]
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
vect.fit(corpus)
vect.vocabulary_
vect.transform(corpus).toarray()
vect.transform(['수업을 들었다. 수업은 재미있다.']).toarray()
2. TF-IDF (Term Frrequency-Inverse Document Frequency)

- "빈번하게 나타나지만 문장의 특징을 나타내지 않는 단어(전치사 등)의 가중치를 낮출 수 없을까?"에 대한 질문에서 나온 자연어 처리 방식이다. 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법이다.
- TF-IDF는 주로 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있다. TF-IDF는 TF와 IDF를 곱한 값을 의미한다.
- tf(d,t) : 특정 문서 d에서의 특정 단어 t의 등장 횟수.
- df(t) : 특정 단어 t가 등장한 문서의 수.
- idf(d, t) : df(t)에 반비례하는 수.
#### TFIDF ####
from sklearn.feature_extraction.text import TfidfVectorizer
tfidv = TfidfVectorizer().fit(corpus)
tfidv.transform(corpus).toarray()
3. Word2Vec

- 앞선 두 방식은 순서를 고려하지 않는 단점이 있다. 따라서 주변의 맥락으로 단어를 표현해보자는 것이 Word2Vec의 탄생 비화다.
- 1) 초기 단어를 임의의 배열로 세팅
- 2) 주변 단어의 배열로 관심단어 배열을 만들자.
- 3) 이 과정을 내가 가진 모든 텍스트에 대해 반복하여 학습
-> 더 적은 크기의 배열로 훨씬 많은 단어 표현 가능. - (Bag of words의 discrete함 극복 -> continuous Bad of Words (CBOW)라고도 함)
- 유사 단어끼리 유사한 배열을 가질 수 있으므로 이를 더하고 뺌으로써 단어 사이의 관계를 파악할 수 있다. (king - man + woman = queen ??!!!) 아직까지도 많이 쓰이고 있으며, 매우 느린 딥러닝에 비해 빠른 속도를 장점으로 상용화되었다.
- 참고로 Word2Vec을 따라한 Stock2Vec, Song2Vec, Doc2Vec 여러가지 나왔다.
#### Word2Vec ####
# make datasets (.txt file)
!wget https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt
import pandas as pd
df = pd.read_csv('ratings_train.txt', sep='\t')
doc = list(df['document'])
with open('ratings_train_text_only.txt', 'w') as f:
for text in doc:
f.write(str(text) + '\n')
# read text file
with open('ratings_train_text_only.txt', 'r') as f:
texts = [str(text).replace('\n', '') for text in doc if len(str(text)) >= 10]
# word2vec training
import os
from gensim.models import Word2Vec
def word2vec(texts):
inputs = [tt.split(' ') for tt in texts]
print('number of text = ', len(inputs))
print('word2vec training...')
model = Word2Vec(inputs, size=50, window=3, min_count=3, negative=5, workers=os.cpu_count(), iter=10, sg=1)
model.init_sims
model.save('word2vec')
word2vec(texts)
w2v = Word2Vec.load('word2vec')
# 단어 벡터
w2v.wv['감동']
# 유사 단어
w2v.wv.most_similar('사랑')4. fastText
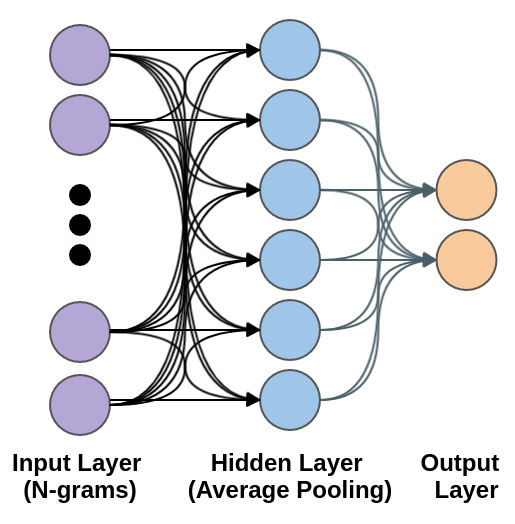
- 단어를 문자 단위로 쪼개서 각 조각마다 word2vec을 수행하여 중간에 오타가 있어도 합리적인 결과를 얻을 수 있다는 것이 최대 장점이다. 한글의 경우 자모로 쪼개서 할 경우 성능이 더 향상된다.
- 단점으로는 동음이의어를 구분할 수 없다(horse와 mouth 맥락이 혼재됨)는 것과 단어 단위로 학습하다보니 문장 단위의 맥락을 이해하지 못한다는 것이다.(거기서 등의 지칭어를 이해하지 못함.)
#### fastText ####
# fasttext training
import os
from gensim.models import FastText
def fasttext(texts):
inputs = [tt.split(' ') for tt in texts]
print('number of text = ', len(inputs))
model = FastText(inputs, size=50, window=3, min_count=3, negative=5, workers=os.cpu_count(), iter=10, sg=1)
model.init_sims()
model.save('fasttext')
print('fasttext is trained')
fasttext(texts)
w2v = Word2Vec.load('word2vec')
fasttext = FastText.load('fasttext')
fasttext.wv.most_similar('고능학교')
참고 자료
- https://austingwalters.com/fasttext-for-sentence-classification
- https://jalammar.github.io/illustrated-word2vec/
- https://wikidocs.net/31698
- https://morioh.com/p/e88b2d2136ac
- https://wikidocs.net/22650
반응형




댓글